If you’ve spoken to me in the last year, you know I can’t stop talking about server-side tagging! It’s a major breakthrough in data collection and marketers are taking notice, especially with the conversation around 3rd party cookies heating up (mmmm… warm cookies).
But what actually is Server-side tagging, and what problems does it solve? Many of us have heard (or are even using) Facebook’s CAPI or the TikTok events API, but don’t fully understand why we need to set it up.
I’m going to explain these points so you can confidently enter this new era of data collection and make informed decisions, particularly as we are heading toward some pretty major milestones such as Google deprecating 3rd party cookies in 2024.
For those of you who are new to Google Tag Manager, let’s start with a little background. It is a free tool that allows you to quickly and easily add tracking and measurement resources (such as the snippets provided by Facebook and Google Analytics) to your website or mobile app. It allows marketers and analysts to manage and deploy these tracking tags without the need to directly modify the source code of your website or app (which is a dream for developers and marketing teams alike).
Google Tag Manager (GTM) has come a long way since I started using it back in 2013. The current version has a sleek interface and powerful collaboration features, such as version control, proposal workflows, workspace isolation to prevent change collisions, and environment management for easier pre-production testing. It’s no wonder that GTM is used by over 27 million websites worldwide (source: BuiltWith Trends).
Ok, enough of me fanboying over Google Tag Manager and let’s get back to the topic of Server-side tagging. To properly understand the Server-side aspect of this new tagging paradigm, let’s start by exploring what Server-side and Client-side contexts actually are. This will make our journey much easier.
Join Me on the Server-side
So what does it mean to be Server-side as opposed to Client-side? Sounds to me like Star Wars fan fiction written by Computer Science nerds. Server-side and Client-side are simply terms that refer to the location where certain tasks or processes are performed in a computing environment.
In traditionally technical terms, Server-side refers to tasks or processes that are performed on a server, which is a computer or device that provides resources, services, and data to other devices or computers on a network. Client-side, on the other hand, refers to tasks or processes that are performed on a client device, such as a personal computer, smartphone, or tablet.
To make this clearer, let’s put this in more human terms. It’s 8:30 PM after a productive yet tiring day and you are supposed to have a friend over for dinner. You quickly realise that trying to make food now would result in you and your friend eating quite late, so you call your friend to ask if they are ok with getting take-out from your local Italian restaurant.
Your friend agrees that this would be a grand idea and says that they will pick up the order on their way to your house. With that, you walk to your fridge to find the menu for the Italian restaurant stuck to it with an “I love Tasmania” magnet, and you proceed to dial the phone number on the front.
A person from the Italian restaurant answers and asks for your take-out order, to which you respond your usual answer with the rehearsed precision of a dramatic stage actor reciting a Shakespearean sonnet:
“I’d like to order beef ragu with fettuccine, extra parmesan and a peach iced tea, please. Make that two of everything please…”
The staff member takes note of your order and conveys it to the kitchen. The chefs get to work making the delicious comfort food that is your ragu. Soon enough, just as the waiter hears the familiar ‘ding’ of the bell from the kitchen, your friend arrives outside the restaurant. The restaurant waitstaff hands your order to your friend who, with the haste of a person who is late to complete their tax return, delivers it directly to your door. You both unashamedly devour your food with an impetuosity that even the most accomplished champion speed eater would be intimidated by.
In this scenario, you are the ‘Client’ and the restaurant is the ‘Server’; as a client, you don’t really see what happens in the restaurant, but it’s where all the magic happens, all off the back of your request. Let’s not forget to give some credit to your wonderful friend, for without them, you would have never got your order. Your friend can be thought of as the network.
So, let’s quickly summarise these points as we will come back to them later:
- You are the Client
- Your Friend is the Network
- The Restaurant is the Server
In this scenario, you could have made dinner at your house (Client-side), but you decided to delegate the actual creation of your food to the restaurant (Server-side). Not only was this quicker for you (allowing you to do other things, such as tidy your house before your friend arrived so as to create the illusion that you are always supremely neat and organised), you knew that the restaurant’s kitchen would have ingredients that you don’t have at home, allowing them to properly customise your order (without you having to go to the store).
The Client and Server are really just different contexts for actions to occur in; some of the actions can be undertaken in both (e.g. your dinner could have been made at home or in the restaurant) while some others cannot. The same is true in a technical context as it relates to Client and Server-side Google Tag Manager environments.
As it relates to the topic of data collection on the web, your browser is a client; it communicates with various servers, such as those run by Google and Facebook, over your network (i.e. your WIFI at home) to send and receive data. All of this happens when you ‘Tag’ your website with marketing and analytics resources such as Google Analytics tag and Facebook pixel.
What Is Tagging?
Let’s pause for a moment and discuss what Tagging is. In the context of Google Tag Manager, and web analytics in general, Tagging is the act of adding marketing code snippets from vendors (e.g. Facebook and Google Analytics) to a website or app. These code snippets are used by vendors to measure user actions, such as purchases, page views, or form submissions.
You may have heard the term ‘Pixel’ from vendors such as Facebook and Snapchat, and they are exactly that; the code snippets you add to your website load the resources required to generate a 1×1 pixel graphic, which is often transparent (so as to not be visible to the end-user). The actual pixel ‘image’ is generally hosted on a server run by the vendor.
In fact, if you navigate to https://www.google-analytics.com/collect, you will see that your browser will load a black screen with a tiny white dot in the middle. This is why we use the term “Pixel”: because these tracking codes often load a 1-pixel website. But how does this Pixel send data to Google or Facebook?
The snippet of code you add to your site generally has 2 core jobs (among others):
- Load the code required by the vendor to compile information about the user, such as the size of the screen on the device they are using, the traffic source the user arrived on the site from, and so on.
- Load and execute the code required to transmit the data to the vendor’s servers for processing. In the case of Google Analytics, this is achieved by adding an image tag with a link to the 1×1 pixel image to your site, appending all of the data collected in step 1 (above) to the end of the URL.
Every time a user visits a site with a certain pixel, the pixel server logs the action. This allows advertisers to track the user’s journey and retarget them with tailored ads. Cookies are used to contextualise all of a user’s events (transmitted by a Pixel, and stored by a vendor on their servers), between sessions.
Below is an example of the Facebook Pixel which you can add to your site by adding it to your website’s source code, or by using Google Tag Manager.
<!-- Facebook Pixel Code -->
<script>
!function(f,b,e,v,n,t,s)
{if(f.fbq)return;n=f.fbq=function(){n.callMethod?
n.callMethod.apply(n,arguments):n.queue.push(arguments)};
if(!f._fbq)f._fbq=n;n.push=n;n.loaded=!0;n.version='2.0';
n.queue=[];t=b.createElement(e);t.async=!0;
t.src=v;s=b.getElementsByTagName(e)[0];
s.parentNode.insertBefore(t,s)}(window, document,'script',
'<https://connect.facebook.net/en_US/fbevents.js>');
fbq('init', '1234567890');
fbq('track', 'PageView');
</script>Instead of manually adding code to our source code (e.g., asking developers to do it for us), we can use Google Tag Manager. We simply set a trigger and we’re done. The same can be done with the Google Analytics snippet, TikTok tags, and many others.
Client-Side Tagging
Alright, now we’re getting to the heart of the article. We’ve discussed a lot of topics, and now it’s time to put it all together. Up till now, the data collection patterns we have discussed so far would all be described as Client-side Tagging. The reason for this is that the user’s browser (the Client) does most of the heavy lifting, from downloading the vendor’s code from their servers, to executing it and passing data back to the vendor.
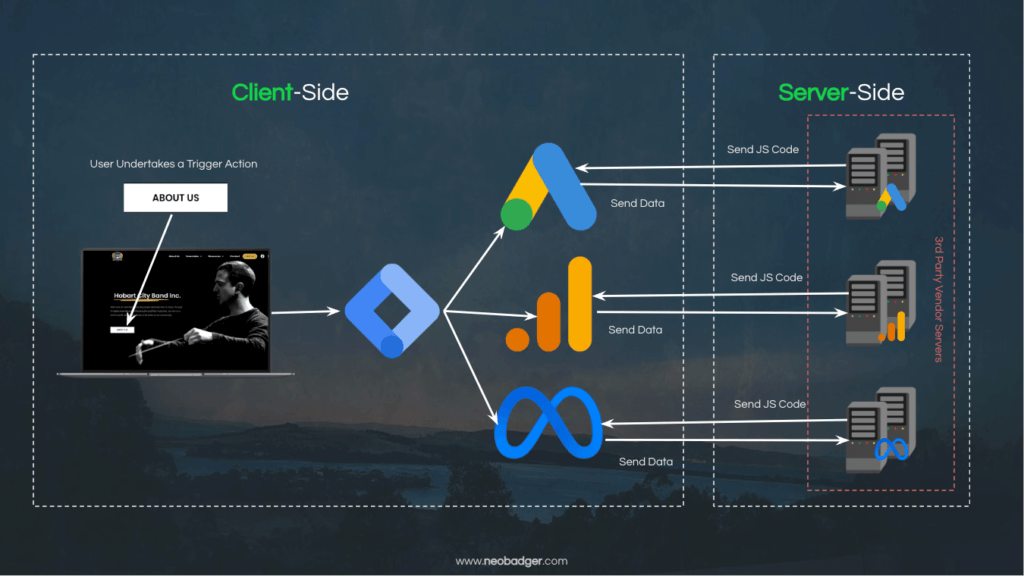
Regardless of how you choose to implement your tag (with or without Google Tag Manager), there are some issues that you will encounter when using a Client-side tagging pattern. These issues relate to the resilience of our tracking, and the obligation we have to protect our users from unnecessary data exposure (particularly if they don’t wish to be tracked on your site).
Content Delivery Networks
As we now know, one of the core functions of a tracking tag is to download the code needed to package and transmit data to vendors. Generally, this code is loaded from a Content Delivery Network (CDN) which may or may not be owned by the vendor (for instance, if they use a public CDN such as UNPKG or JSDelivr.
While CDNs are an effective way to make content more accessible over a network (allowing for faster downloads), the user’s IP address is sent to the CDN, where their location is determined so that a nearby edge node can be used to serve the requested asset. This exposes the user’s data to an additional party before any tracking begins (if the vendor is using a third-party CDN).
Additionally, the user’s device and browser security settings must permit the resource to be downloaded from the chosen CDN. Ad-blocking technology or strict firewall settings may cause these requests to fail.
Cookies, Cookies, Cookies
I bet you were wondering how long I could go talking about tracking without mentioning the ‘C’ word. Yes, cookies are (unsurprisingly) a weakness here, for several reasons.
Whenever network communication occurs from the user’s browser to the vendor’s servers, any cookies set by the vendor are also sent, allowing the vendor to read their content. This happens when the code needed to package and transmit the data is initially downloaded by the vendor’s code snippet, or when data is sent (e.g. when a purchase or page view event is triggered). This is assuming the browser allows 3rd party cookies, such as Google Chrome at the time of writing.
Now, I understand this isn’t an article about third-party cookies. However, this is an important point to cover, as it will be crucial in 2024, when Google Chrome joins other browsers such as Brave, Safari, and Firefox and begins blocking third-party cookies.
As you likely know, third-party cookies are simply cookies that are set by a website other than the one you are currently visiting. While not exclusively used for marketing and analytics purposes, their bad reputation comes as a result of their use by advertisers to track online activities across different websites and to deliver targeted advertisements to users.
To illustrate this, let’s say you go to teabagcentral.com using Google Chrome, and a cookie is set by google.com in the course of executing the Google Analytics tag. This cookie, as well as any other cookies set by google.com, even if these cookies were set on a different website (we refer to this as cross-site tracking) and even a different session, would be accessible to Google over the network as part of this request.
Additionally, since the script is executed on the page using JavaScript (the snippet we saw above is JavaScript), they can also set and access cookies in a first-party context. This theoretically allows them to access the values of any cookies set by teabagcentral.com, even if they are not intended for tracking.
Outside of the security issues that this can cause, the concern here is that teabagcentral.com only intended to send data to Google Analytics, but Google could theoretically use this data to build a much more comprehensive identity graph of users by exploiting this method.
Now, this is just an example, and I am not saying that Google is absolutely doing this, but it is clear how this can compromise a user’s privacy. That’s why the privacy community has been pushing for 3rd party cookies to be eliminated.
Cross-site Tracking Prevention
If you have been active in the web analytics and marketing community over the last few years, you will have almost certainly heard of Intelligent Tracking Prevention. As a refresher, ITP, or Intelligent Tracking Prevention, is a privacy feature built into the Safari web browser that aims to protect users’ privacy by limiting the ability of third-party websites to track their online activities.
When ITP is enabled, Safari blocks third-party cookies, which are used by advertisers and other third parties to track users’ online activities across different websites. ITP also limits the amount of time that a third-party cookie can remain on a user’s device, making it more difficult for advertisers to build up a long-term profile of a user’s interests and behaviours.
ITP was introduced in 2017 with the release of iOS 11 and macOS High Sierra, and has since been updated several times to include new features and enhance its privacy protections. It is designed to help users maintain more control over their online privacy and to prevent advertisers and other third parties from collecting and using their data without their knowledge or consent.
Apple’s focus with ITP is not to prevent tracking from occurring on a website at all; they are generally fine with the tracking from occurring (provided the user consents to this) as long as the data collected is discreet to the website the user is accessing. Rather, their focus with ITP is to limit vendors’ and marketers’ ability to track users between sites using the methods mentioned in the Cookies section, above.
Personally Identifiable Information Leaks
This is a really common one, and really the most salient point of those mentioned thus far. I spent most of 2016 reviewing the Google Analytics accounts of organisations to ensure that no personally identifiable information (PII) was propagating as a result of their data collection scheme, ahead of the enactment of the General Data Protection Regulation (GDPR).
Whilst Google strictly prohibited users of the Analytics product from sending PII to their servers, you would be surprised (if not horrified) how common it was, and still is for that matter. I have seen significant amounts of PII being sent and rendered into reports from organisations of all sizes, from federal government agencies, and organisations listed on the stock exchange, through to small start-ups.
Most of the time, the personal information that was shared was done so unintentionally, for instance in URLs (such as following form submission using a GET method), or in page titles (very common when personalisation is used). Regardless of how it ended up there, at best it is a violation of Google’s terms of service (resulting in the complete deletion of all affected data and even account suspension) and at worst can be outright illegal.
Remediating PII leaks can be difficult, as it may involve changing core website or app features or restructuring data collection to stop PII from being sent to Google Analytics servers. This can be impractical, time-consuming, and very expensive. So far, we have spoken extensively about how tagging works, and the shortcomings of the current tracking paradigm. Everything we have spoken about above falls within the Client-side context. Thankfully, Server-side tagging can help us here.
Server-Side Tagging
We can see that there are a number of issues with the Client-side tagging model, and I have not listed all of them for the sake of not having this article get any longer than it already is! Thankfully, Server-side tagging can help us overcome many of these issues, and make it much simpler to apply mitigations for issues that require manual intervention (such as PII remediation).
The concept of Server-side tagging is very similar to Client-side tagging, in that you still have vendors that need to receive data about events on your site that you deem important, such as a conversion like a purchase. The difference is that instead of the browser communicating directly with vendors, we add an intermediary piece of technology that acts as a buffer between the browser and the vendor.
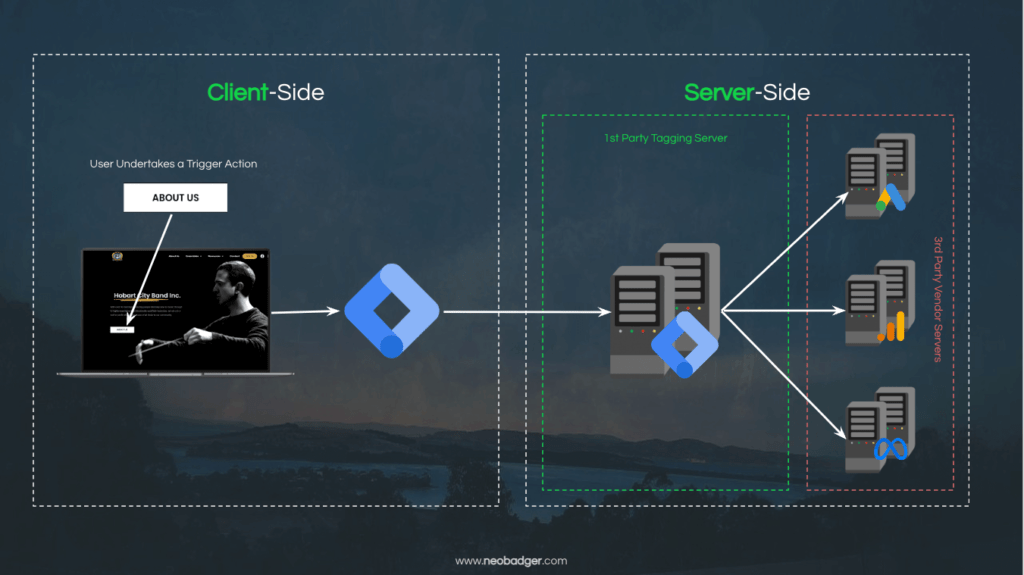
This buffer is what Google calls a Server-side container, and it essentially allows us to stage our data in a secure, first-party environment before sending it to a third-party vendor. Let’s unpack this notion of a ‘secure, first-party environment’ a little.
If you run a website, it’s likely that you are paying for a server to host your website, be it one that you manually provision or which has been provisioned for you (as in the case of Shopify or SquareSpace). On this server, you can store almost anything (within your service provider’s terms and, of course, the law), making it a part of your first-party infrastructure.
Similarly, you can provision a server on which you have a Google Tag Manager container instance ‘running’. The Server-side GTM container operates in a similar way to a Client-side container, in that it listens for events, can send data to vendors and so on.
So how does the Server-side container receive data from the Client-side (user’s browser)? Let’s assume you have joined the Google Tag Manager appreciation society with me (I’ll send you a membership card and some branded merch) and have added the code snippet to your website’s source code. In the GTM container, you have already added some Google Analytics tags.
As we know from our discussions on Client-side tagging, the Google Analytics configuration tag loads all the resources the browser needs to know what data to collect and how to send it to Google Analytics servers. But we don’t have to have it operate that way. Instead, we can configure our GTM container and our Google Analytics tags to receive and send data directly from our Server-side container. The Server-side container will receive the data and then go on to forward it to Google’s servers from directly within our Server-side container.
Have we not added an extra step here without any real benefit? No, because even before we do anything cool, we have unlocked some really powerful features which are simply not available on the Client-side. Let’s explore what we have unlocked:
Stream Consolidation
In the world of data collection, a stream is simply a vector of data that comes from your website or app (though a user action for instance) and is sent to various platforms for reporting and marketing purposes.
For instance, if you have an e-commerce website, you might want to track ‘Add to Cart’ events in Google Analytics, Facebook Ads, Google Ads, Klaviyo, and Tiktok. In a Client-side context, you would need to set up a tag for every one of these vendors, as they all have slightly different data collection schema, and also need to be sent to different destinations. And this is likely the case for other events too, such as purchases, product detail views, and so on.
This is a lot of work for a user’s browser and network: downloading all of the code from all the browsers, executing it all, and seeing the data back to the vendors. It appears that there is a lot of duplication, especially when we consider how similar the data we need to send to each vendor is, albeit in different formats.
// Facebook Purchase Event
fbq('track', 'Purchase', { currency: 'AUD', value: 30.00 });
// TikTok CompletePayment Event
ttq.track('CompletePayment', { currency: 'AUD', value: 30.00 });
// Klaviyo Custom Purchase Event
_learnq.push(['track', 'Purchase', { Price: 30.00, ProductID: 'P0T4TO'} ]);What if we could just send the data once from the Client-side Google Tag Manager container to the Server-side container and have the Server-side container do all the heavy lifting? Well, the grand news here is that we can!
Doing so can be a significant performance win for website owners as you are no longer burdening your user’s browsers with all this work, freeing up their network and device resources for your website’s assets and not that of your vendors. For websites with loads of Client-side tags (one of my clients has hundreds of events and over a dozen different vendors), the performance gains will be quite measurable.
Hit Validation
Another win for Server-side tagging is the ability to undertake more meaningful hit validation. This is an important step in the data collection process because it helps to ensure that the data being analysed is accurate and reliable, and that it properly reflects the performance of the website or app. This includes detecting and excluding traffic from bots, scrapers, and other automated sources that may generate false or misleading data.
Additionally, we can pre-process the data and remove any PII which might have mistakenly propagated into the data packet. This allows us to act more quickly to resolve PII leaks and do so more cost-effectively, as we do not need to involve our development team before we can engineer a fix. Of course, you should always try and resolve PII leaks at the source, but patching the leak in the meantime is always a good thing for the end user.
By performing hit validation in our Server-side container, we can filter out this type of traffic and focus on valid data from genuine users before the packet of data is even sent to the vendors.
True IP Anonymisation
Google has introduced a feature to anonymise user’s IP addresses as a response to concerns that EU regulators are having. However, this has proven to be insufficient (read more in my article: ‘Is Google Analytics GDPR compliant?’) and so further action has been recommended by regulators to prevent the transmission of users’ IP addresses to vendors.
The only way to truly achieve this at the time of writing is by using a server-side proxy such as a Server-side GTM container, allowing us to mask or completely remove the user’s IP address. This eliminates the problems discussed in the preceding section on Client-side tagging, where a user’s IP address is sent with all requests, including to any gateways, such as Content Delivery Networks (CDNs), and ultimately to vendors.
With Server-side tagging, the only person who will have access to the user’s IP address is you, as the owner of the server (assuming you, yourself are not using a CDN for your website caching).
Consent Management
This is a particular challenge for those of us who are trying to balance our obligations under the CCPA, LGPD, and the GDPR, as we have had to manage content controls in our Client-side container, adding extra burden for our user’s browser.
Now, we can delegate this to our Server-side container. If you are using a cookie banner that manages consent and stores a first-party cookie, and your Server-side GTM container uses your website’s domain as its endpoint URL (more on this point below), then you can receive the value of the content from the request sent from the Client-side.
Even if a user decides that they do not which to participate in sharing personal data (though cookies for instance), you can still collect some data after sanitising any PII out of the data you plan on forwarding to your vendor, allowing you to balance data collection whilst respecting your users’ privacy.
Overcome Tracking Prevention Limitations
We spoke about Intelligent Tracking Prevention (ITP) in the above section on Client-side tracking limitations (see Cross-site Tracking Prevention), and it has had a real impact on marketers who get a lot of Safari users to their sites.
ITP significantly limited the lifespan of first-party cookies set with JavaScript, such as those set by Google Analytics and Facebook pixel. These cookies are deleted after 7 days, or as soon as 24 hours after creation. This causes a significant loss of definition in the user journey and traffic source attribution, especially if the lead-to-conversion time was longer than 7 days.
Server-side tagging can overcome this by setting these cookies in the response directly from your tagging server. Safari’s ITP will treat them the same way as any first-party, server-set cookie and let them effectively remain indefinitely.
We can overcome tracking prevention methods such as VPNs, adblockers, browser-native features, and more, in a similar way as described above. Essentially, if you have configured your tagging correctly, ad blockers will not be interested in blocking, as it could be any other resource your website relies on.
Why Server-Side Tagging?
You now understand Server-side tagging and how it differs from Client-side tagging. We also discussed some of the restrictions of Client-side tagging and how Server-side tagging can help address them. So let’s boil this down to the fundamental reasons people are choosing a Server-side tagging environment for their data collection scheme:
Ownership
When using a Server-side tagging implementation, you own the server container. It does not run on infrastructure which is exclusively controlled by Google, but rather on your own, similar to your website. Naturally, Google supplies the Google Tag Manager application layer (i.e. the interface from which you can create your tags, triggers, variables and so on), but outside of that, you can completely choose how you use the Server-side container itself.
Portability
You don’t have to use Google’s server infrastructure to host your Tagging server. It uses Docker under the hood, a tool that packages and deploys applications in a containerised format, making it highly portable. This means you can run it on any cloud infrastructure that supports Docker, including Amazon AWS, Microsoft Azure, and even on-premises.
Naturally, you will need to pay for the use of a server if you choose a cloud provider such as Google Cloud Platform, AWS, or Azure, but the costs are generally fairly low, even for a site that has a large amount of traffic, many events, and a sizeable list of vendors to send data too.
Performance
Server-side tagging allows you to shift the burden of downloading, executing, and sending data to vendors from the user’s browser to the server.
This reduces the load on the user’s network and device resources, which is especially beneficial for websites with many client-side tags. It frees up resources for the website’s assets, instead of those of vendors, improving performance and the user experience.
Truly First-Party
By far the most exciting feature here is the ability to proxy requests for a third-party vendor through the Server-side container, allowing the Client-side request to be fully first-party. For instance, when you add your Client-side Google Tag Manager container to your source code, it will look something like this:
<!-- Google Tag Manager -->
<script>(function(w,d,s,l,i){w[l]=w[l]||[];w[l].push({'gtm.start':
new Date().getTime(),event:'gtm.js'});var f=d.getElementsByTagName(s)[0],
j=d.createElement(s),dl=l!='dataLayer'?'&l='+l:'';j.async=true;j.src=
'<https://www.googletagmanager.com/gtm.js?id='+i+dl;f.parentNode.insertBefore(j,f)>;
})(window,document,'script','dataLayer','GTM-XXXXXX');</script>
<!-- End Google Tag Manager -->Pay attention to the URL in the above code snippet at line 5. Ad blockers, VPNs with anti-tracking features, and some browsers (such as Brave) look for this domain and know they need to block it. But what if we could proxy the request to www.googletagmanager.com through our own domain?
We can absolutely do that with Server-side GTM. This means that our snippet would look something like this (take note of line 5 once again; I have replaced the GTM domain with my own):
<!-- Google Tag Manager -->
<script>(function(w,d,s,l,i){w[l]=w[l]||[];w[l].push({'gtm.start':
new Date().getTime(),event:'gtm.js'});var f=d.getElementsByTagName(s)[0],
j=d.createElement(s),dl=l!='dataLayer'?'&l='+l:'';j.async=true;j.src=
'<https://track.neobadger.com/gtm.js?id='+i+dl;f.parentNode.insertBefore(j,f)>;
})(window,document,'script','dataLayer','GTM-XXXXXX');</script>
<!-- End Google Tag Manager -->This feature allows us to unlock the full power of Server-side GTM, with a truly first-party solution.
Security
A nice byproduct of this change is that your developers of the cyber security team will no longer need to maintain your Content Security Policy (CSP) every time we want to add a new tracking vendor to the website. For context, a CSP is a rule that can be applied to a server or edge infrastructure. It designates a list of allowed sources that a webpage can load, such as Google.com or Facebook.com, as well as the resource.
In addition, by not loading a lot of third-party JavaScript resources on your site, you are limiting your exposure to a supply chain attack. This is when one of your vendors is compromised, which could lead to any website running their code being compromised as well.
Preprocess Control & Enrichment
We can now wait until the data reaches our Server-side GTM container before we process it, should we need to undertake some form of data transformation, redaction, or enrichment. We have already spoken about the performance benefits of delegating resource-heavy tasks to the server, but that is not the only benefit here.
Additionally, we can effectively eliminate order-of-execution issues that may arise on the Client-side due to asynchronous resource execution. This allows us to manage our transformations in a much more reliable way, without the risk of side effects or unpredictable race conditions.
Given that our data is sent over the network to a server we control, we have many additional signals to create variables from. Where? The HTTP headers, of course! This means that we are no longer beholden to the quirks of browser-level APIs for User-Agent data (which has been significantly degraded over the years. We can further enrich our data, (provided it is permissible under the applicable privacy laws), to leverage headers forwarded via our Content Delivery Network (CDN) for more precise location data.
I am currently in the process of drafting an API that can run in a Server-side GTM container which will run a query using a customer ID (received when a user has logged in, collected on the Client-side) against my client’s CRM to get a rich set of anonymous customer definitions for use in Facebook audience creation. We can do all of this without exposing data on the Client-side.
Should I Ditch Client-Side Tagging?
There is no hard and fast answer to this question. I will say that if you do choose to use Server-side tracking, you must do so with a privacy-first mindset, as with great power comes great responsibility. You can essentially bypass the protections afforded to users in their browser (as discussed in the above section: ‘Overcome Tracking Prevention Limitations’), and for those who are using further privacy-preserving technology (such as an ad blocker or VPN), then I strongly believe you must honour that as best as you can.
My hope is that there are better controls for this in the future, such as a more universal (and properly adopted) privacy opt-out pattern that can signal to a Client-side server that somebody wishes to opt-out of tracking (using passive signals, such as HTTP headers). Until such a time, we must be mindful that we have a responsibility to protect the end user, even if we have the power to circumvent their protections if we so choose.
Just to clarify a point that often confuses people, if you do plan to go the first-party Server-side GTM route and you are currently using Google Tag Manager on the Client-side, you will do well to keep your Client-side container operational. The reason for this is that we still need to be able to capture events and transfer data to your Server-side endpoint.
Also keep in mind that the server you choose to host your Server-side GTM instance will cost money to run, just as your website server does. Most cloud infrastructure will bill on a request and execution runtime base, and so it is very important that you have this set up properly so that you don’t end up with a massive bill each month.
In addition, this is a privileged environment to which you are sending a lot of data so it is important that you have it properly secured so that you don’t end up with any surprise data breaches that result from poor operations security.
I highly recommend that you get an expert to help you find the server that best suits your budget and tagging needs. With that in mind, you can manage your server for a low cost; entry-level servers with limited scalability start at just $30 USD per month, and for particularly simple tagging needs on a low-traffic volume site, can be set up with no ongoing cost at all.
Final Thoughts
Server-side tagging provides numerous advantages when it comes to data collection and analysis, from improved performance to increased security, privacy and control over our data. We can pre-process and enrich our data before it is sent to vendors, but it is also essential to consider the cost of running the server and the responsibility of managing it securely and cost-efficiently.
Additionally, if you choose to switch to Server-side GTM and already have a Client-side GTM instance running, I recommend that you keep your Client-side container remains operational, as it will continue to streamline the capture and transfer of data to the Server-side endpoint. It is worth taking the extra time and effort to use your domain as the URI endpoint so you can unlock the full suite of benefits that come with Server-side tagging (though you do need to be careful when doing this).
When making the decision of whether or not to use Server-side tagging, it is important to consider the full range of advantages and disadvantages of this method. It is important to take into account the cost of running the server and the technical requirements needed to maintain it.
If you do choose to go down the Server-side tagging route and you are not sure how to set up and configure a server, I highly recommend you reach out to an expert so you can avoid the pain of a massive server bill, outages resulting from misconfigured DNS settings, or leaks resulting from poor operational security.
With a properly configured server and GTM container, and a privacy-first mindset, the benefits of using a Server-side GTM configuration speak for themselves; not only are you able to unlock more reliable and signal-rich data, but you can protect and enhance your user’s experience by managing the transfer of data to vendors ethically and efficiently.

